

Research Summary
My current research interests in computer vision and machine learning are in deeper understanding of discriminative convolutional neural networks and their feature representations. Particularly, I am interested in the compression of convolutional neural networks. I am also highly interested in several application areas therein such as domain adaptation, task transfer and medical image lesion detection and identification.
My doctoral dissertation involved work in multiple instance learning, in designing statistical learning algorithms and image feature design. In particular I was interested in developing assistive technologies for ophthalmological-clinical purposes.
I was also involved in an intelligent transport system development project called the MIDAS project, where my research included detection algorithms for detection of lanes, lane-markers, prediction of lanes, self-positioning of vehicles on-road, detection of cars, sign boards, anomalies and situational awareness. The project involved building of smart car networks towards reduced road congestion. It used several Bayesian modelling systems to achieve the same. I was also involved in a similar research effort vehicle detection at Intel as a co-op for 8 months. That work involved methods similar to deformable part models and regionlets.
My masters research was directed towards image/video interpolation, where I worked on video de-interlacing using control-grid interpolation. My research included visual-saliency detection and quaternion mathematics for images.
For my research internal to AWS, please look me up on phonetool.
Interests
- Neural Network Compression
- Domain Adaptation
- Convolutional Neural Networks
- Multiple instance learning
- Lesion detection
- Clinically relevant retrieval
- Video De-Interlacing
- Image Interpolation
Research Projects
-

Yann is a toolbox designed for the easy construction, use and study of deep neural networks. Yann is built to support any kind of a DAG architecture of network with plug and play layers, modules and other tools. Yann supports a lot of recent research and is designed to be student and industry friendly. It is a toolbox that is designed on the theano backend. There are also pre-trained models that are available through yann so that one can simply download and use. The toolbox can be found here.
There were several publications all of which can be found in the publications page. I also wrote a tutorial for migration from theano to tensorflow. It is available here.
-
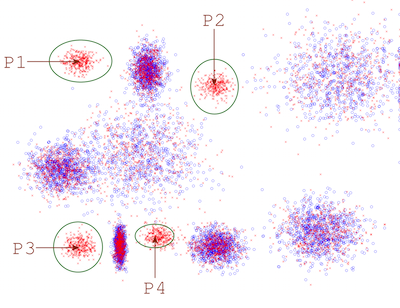
Multiple-instance learning (MIL) is a unique learning problem, where labels are provided only for a collection of instances called bags. There are two types of instances: negative instances, which are found in either negative bags or positive bags, and positive instances, which are found only in positive bags. While a positive bag should contain at least one inherently positive instance, a negative bag must not contain any positive instances. In MIL, labels are not available on the instance level. One may attempt to learn instance-level labels during the training stage, thus reducing the problem to an instance-level supervised classification. Alternatively, one may also localize and prototype the positive instances in the feature space and then rely on the proximity to these prototypes for subsequent classification. In this project we study the use of non-parametric methods and Deep Learning for MIL.
For full description, papers and code go to the Project Page
Collaborators include: Parag Shridhar Chandakkar, Dr. Baoxin Li
-
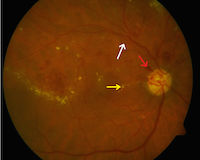
Diabetic retinopathy (DR) is a vision-threatening complication that arises due to prolonged presence of diabetes. When detected and diagnosed at early stages, the effect of DR on vision can be greatly reduced. Content-based image retrieval can be employed to provide a clinician with instant references to archival and standardized images that are clinically relevant to the image under diagnosis. This is an innovative way of utilizing the vast expert knowledge hidden in archives of previously diagnosed fundus camera images that helps an ophthalmologist in improving the performance of diagnosis.
In this project we invented multiple-instance based retrieval systems such as Rank-KNN, to perform the retrieval task. We also employed MIL based ideas to perform both regular and hierarchical classification. These ideas we believe will help the diagnosis process on the initial stages, where we visualize nurses who are not trained as well as doctors in initial pre-diagnosis filtering.
For full description, papers and code go to the Project Page
Collaborators include: Dr. Baoxin Li, Parag Sridhar Chandakkar and Dr. Helen Li
-
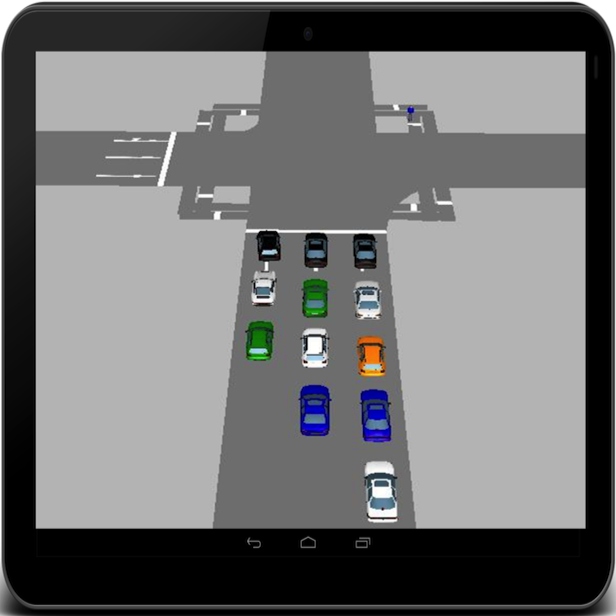
The objective of the project is to demonstrate the synergistic use of a cyber-physical infrastructure consisting of smart-phone devices; cloud computing, wireless communication, and intelligent transportation systems to manage vehicles in the complex urban network - through the use of traffic controls, route advisories and road pricing - to jointly optimize drivers' mobility and the sustainability goals of reducing energy usage and improving air quality. The system being developed, MIDAS-CPS, is to proactively manage the interacting traffic demand and the available transportation supply. A key element of MIDAS-CPS is the data collection and display device PICT that collects each participating driver's vehicle position, forward images from the vehicle's dashboard, and communication time stamps, and then displays visualizations of predicted queues ahead, relevant road prices, and route advisories. Given the increasing congestion in most of the urban areas, and the rising costs of constructing traffic control facilities and implementing highway hardware, MIDAS-CPS could revolutionize the way traffic is managed on the urban network since all computing is done via clouds and the drivers instantly get in- vehicle advisories with graphical visualizations of predicted conditions. It is anticipated this would lead to improved road safety and lesser drive stress, besides the designed benefits on the environment, energy consumption, congestion mitigation, and driver mobility. This multidisciplinary project is at the cutting edge in several areas: real-time image processing, real-time traffic prediction and supply/demand management, and cloud computing. Its educational impacts include enhancements of curricula and laboratory experiences at participating universities, workforce development, and student diversity. Additional information on the project is available here.
Collaborators include: Dr. Baoxin Li, Parag Sridhar Chandakkar, Dr. Pitu Mirchandani, Dr. Dijiang Huang, Yuli Deng, Yilin Wang
-

The problem of front-collision warning is an involving task comprising of various fields including image processing, machine learning and computer vision. Front-collision warning involves detecting objects in front of the car while driving including other cars, pedestrians and other hitherto unseen or unexpected objects. This involves detection recognition and tracking. The work can be viewed in two phases:
- The first phase in this work involved the study, implementation and competitive analysis of various feature extractors and classifiers that are popular in the object detection space.
- The second phase in this work involved the study and development of purpose built graphical models and other part-based-models to fit the world of view from a car’s perspective. Some research was also done on applying similar models to pedestrian and generic objects detection.
Both the above mentioned problems are solved or aimed to be solved in the context of ADAS to provide assistance to drivers to make driving safer and easier. Although theoretically, these algorithms have the potential of being on autonomous vehicles, these are being designed to run on low-budget, low-power IA boards. With the expected addition of cameras into smart-cars provide the perfect Launchpad for such applications to be integrated with vehicles and provide support to the drivers thereby greatly reducing the risk that is seen inherent with driving.
Collaborators include: Dr. Farshad Akhbari, Ed Petryk, Dr. Zafer Kadi, Dr. Lina Karam, Shirish Khadilkar, Charan Dudda Prakash, Tejas Borkar, Vinay Kashyap, Angell Joey and Brittney Russell.
-
With the advent of progressive format display and broadcast technologies, video deinterlacing has become an important video processing technique. Numerous approaches exist in literature to accomplish deinterlacing. While most earlier methods were simple linear filtering-based approaches, the emergence of faster computing technologies and even dedicated video processing hardware in display units has allowed higher quality, but also more computationally intense, deinterlacing algorithms to become practical. Most modern approaches analyze motion and content in video to select different deinterlacing methods for various spatiotemporal regions.
In this project, we introduce a family of deinterlacers that employs spectral residue to choose between and weight control grid interpolation based spatial and temporal deinterlacing methods. The proposed approaches perform better than the prior state-of-the-art based on peak signal-to-noise ratio (PSNR), other visual quality metrics, and simple perception-based subjective evaluations conducted by human viewers. We further study the advantages of using soft and hard decision thresholds on the visual performance.
Collaborators include: Dr. David Frakes and Dr. Christine Zwart,